Traduction de l’article en anglais Linear Sequential Unmasking–Expanded (LSU-E): A general approach for improving decision making as well as minimizing noise and biais, Forensic Science International: Synergy, Volume 3, 2021, 100161, avec l’accord de l’auteur Itiel DROR (contact : [email protected])
Toute prise de décision — et en particulier celle des experts — implique l’examen, l’évaluation et l’intégration d’informations. La recherche a montré que l’ordre dans lequel l’information est présentée joue un rôle crucial dans le processus décisionnel et dans leurs résultats. En effet, une même donnée, présentée dans un ordre différent, peut mener à des décisions divergentes [1,2]. Puisque l’information doit nécessairement être considérée selon une certaine séquence, optimiser cet ordre devient essentiel pour optimiser la qualité des décisions. Adopter une séquence ou une autre est inévitable — un ordre de traitement est toujours utilisé — et, dès lors que la séquence adoptée influence le raisonnement, il est crucial de réfléchir à la manière la plus pertinente d’organiser les informations.
Dans le domaine des sciences forensiques, les approches existantes visant à optimiser l’ordre de traitement de l’information (comme le dévoilement séquentiel [3] ou le dévoilement linéaire et séquentiel — LSU [4]) présentent des limitations, tant en raison de leur champ d’application restreint à certains types de décisions que de leur objectif exclusif de réduction des biais, sans viser une optimisation plus globale de la prise de décision en contexte forensique. Nous introduisons ici le Dévoilement linéaire et séquentiel — version étendue (LSU-E), une approche applicable à toutes les décisions forensiques, et non plus limitée à un type particulier. En outre, le LSU-E ne se contente pas de minimiser les biais : il permet également de réduire le bruit et d’améliorer la qualité globale des décisions forensiques.
Le fondement des biais cognitifs
Tout processus décisionnel repose sur le cerveau humain et sur les mécanismes cognitifs. L’un des facteurs essentiels dans ce processus concerne l’ordre dans lequel l’information est reçue. Il est en effet bien établi que les individus ont tendance à mieux retenir — et à être plus fortement influencés par — les premières informations d’une séquence, en comparaison avec celles qui suivent — un phénomène connu sous le nom d’effet de primauté (primacy effect) [5,6]). Par exemple, lorsqu’on demande à une personne de mémoriser une liste de mots, elle retiendra plus facilement ceux figurant en début de liste que ceux placés au milieu (voir également l’effet de récence [7]).
Fait crucial, les premières informations d’une séquence ne sont pas seulement mieux mémorisées : elles influencent également le traitement des informations suivantes de multiples façons (voir Fig. 1). Ces premières données peuvent générer des premières impressions puissantes, difficiles à remettre en question [8] ; elles suscitent des hypothèses qui orientent l’attention sélective, déterminant ainsi quelles informations seront prises en compte ou négligées [[9], [10], [11], [12]] ; et elles peuvent déclencher une série d’effets décisionnels bien documentés tels que : biais de confirmation, escalade d’engagement, inertie décisionnelle, vision tunnel, persistance des croyances, état d’esprit figé (mind set) et effet d’ancrage [[13], [14], [15], [16], [17], [18], [19]].
Ces phénomènes ne se limitent pas aux décisions en science forensique : ils s’appliquent également aux experts médicaux, aux enquêteurs de police, aux analystes financiers, aux services de renseignement militaire — et plus largement à toute personne impliquée dans une prise de décision.
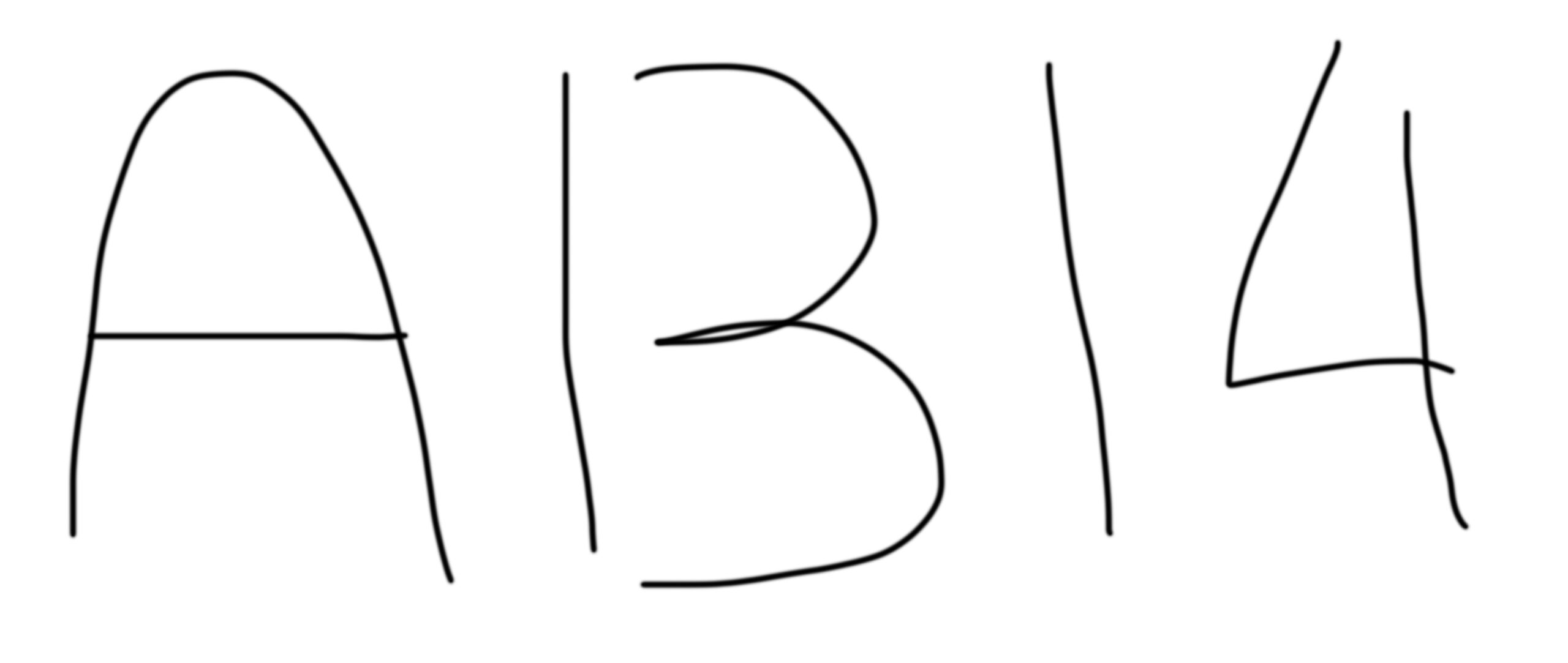
Fig 1 : Illustration de l’effet d’ordre. Prenons une séquence de trois symboles : A–B–14.
Si cette séquence est lue de gauche à droite, le symbole central sera naturellement interprété comme un B. En revanche, si elle est lue de droite à gauche, ce même symbole sera perçu comme un 13. Cela illustre à quel point l’interprétation d’une information peut dépendre des éléments qui la précèdent : l’ordre de présentation influence la perception.
De nombreuses études ont démontré à plusieurs reprises que présenter une même information dans un ordre différent peut conduire les décideurs à tirer des conclusions différentes. De tels effets ont été observés dans une grande variété de domaines, allant de la dégustation alimentaire [20] à la prise de décision par les jurés [21,22], en passant par la réfutation des discours conspirationnistes (notamment les théories du complot anti-vaccins [23]), démontrant ainsi que l’ordre dans lequel l’information est présentée joue un rôle fondamental.
Par ailleurs, ces effets d’ordre ont été spécifiquement mis en évidence dans le domaine de la science forensique. Par exemple, Klales et Lesciotto [24], ainsi que Davidson, Rando et Nakhaeizadeh [25], ont montré que l’ordre dans lequel les os d’un squelette sont analysés (par exemple : crâne avant le bassin) peut influencer l’estimation du sexe biologique.
Contexte des biais
Toute décision est susceptible d’être influencée par des biais cognitifs — c’est-à-dire à des déformations systématiques du jugement [26]. Ce type de biais ne doit pas être confondu avec un biais discriminatoire intentionnel. Le terme « biais », tel qu’il est employé ici, fait référence aux biais cognitifs qui affectent chacun d’entre nous, le plus souvent de manière involontaire et inconsciente [26,27].
Bien que de nombreux experts croient à tort être immunisés contre les biais cognitifs [28], ils y sont, à certains égards, encore plus sensibles que les non-experts [[27], [29], [30]]. En effet, l’impact des biais cognitifs sur la prise de décision a été documenté dans de nombreux domaines d’expertise, allant des enquêteurs judiciaires et des magistrats, aux experts en assurance, aux évaluateurs psychologiques, aux inspecteurs en sécurité et aux médecins [26,[31], [32], [33], [34], [35], [36]] — ainsi que, de manière spécifique, en science forensique [30].
Aucun champ de la science forensique — ni d’ailleurs aucun autre domaine — n’est à l’abri des biais.
Les biais en science forensique
L’existence et l’influence des biais cognitifs en sciences forensiques sont aujourd’hui largement reconnues (on parle notamment de « biais de confirmation en science forensique » [[27], [37], [38]]). Aux États-Unis, par exemple, la National Academy of Sciences [39], le President’s Council of Advisors on Science and Technology [40], ainsi que le National Commission on Forensic Science [41] ont tous reconnu les biais cognitifs comme un enjeu réel et important dans le processus décisionnel en science forensique. Des constats similaires ont été établis dans d’autres pays à travers le monde — par exemple, au Royaume-Uni, le Forensic Science Regulator a émis des recommandations visant à éviter les biais dans les travaux forensiques [42], tout comme en Australie [43].
Par ailleurs, les effets des biais ont été observés et reproduits dans de nombreuses disciplines forensiques (par exemple : dactyloscopie, pathologie médico-légale, génétique, balistique, forensique numérique, expertise d’écriture, psychologie légale, anthropologie forensique, et investigation de la scène de crime, entre autres [44]), y compris chez des experts en exercice dans ces domaines [[30], [45], [46], [47]]. En résumé, aucun champ de la science forensique — ni d’ailleurs aucun autre domaine — n’est à l’abri des biais.
Réduction des biais en sciences forensiques
Bien que la nécessité de lutter contre les biais en science forensique soit aujourd’hui largement reconnue, y parvenir concrètement dans la pratique constitue un tout autre défi. Dans le cadre des contraintes pragmatiques et opérationnelles des scènes de crime et des laboratoires de police scientifique, la réduction des biais ne va pas toujours de soi [48]. Étant donné que la simple prise de conscience et la volonté individuelle sont insuffisantes pour contrer les biais [27], il est indispensable de développer des contre-mesures à la fois efficaces et applicables sur le terrain.
La méthode du dévoilement linéaire et séquentiel de l’information (Linear Sequential Unmasking, LSU [4]) vise à réduire les biais en régulant le flux et l’ordre dans lequel l’information est révélée, de manière à ce que les décisions forensiques reposent uniquement sur les éléments de preuve et les informations pertinentes et objectives. Concrètement, la LSU exige que les décisions comparatives forensiques commencent par l’examen et la documentation des traces issues de la scène de crime (l’élément « de question » ou matériel inconnu), de façon indépendante, avant toute exposition au matériel de référence (le matériel connu, provenant d’un suspect ou d’un object). L’objectif est de minimiser l’effet potentiellement biaisant de l’exposition au matériel de référence sur l’interprétation des traces issues de la scène de crime (voir Niveau 2, Fig. 2). La LSU garantit ainsi que ce sont les éléments de preuve eux-mêmes — et non le profil du suspect ou caractéristiques d’un objet — qui orientent la décision forensique.
Cela est d’autant plus crucial que les éléments issus de la scène de crime sont particulièrement vulnérables aux biais, du fait de leur qualité et quantité d’information souvent limitées, ce qui les rend plus ambigus et susceptibles d’interprétations variables — contrairement aux matériels de référence, généralement plus complets. En procédant d’abord à l’examen du matériel indiciaire provenant de la scène, la LSU réduit le risque de raisonnement circulaire dans le processus décisionnel comparatif, en évitant que l’on ne raisonne « à rebours » depuis l’objet ou le suspect vers la trace.
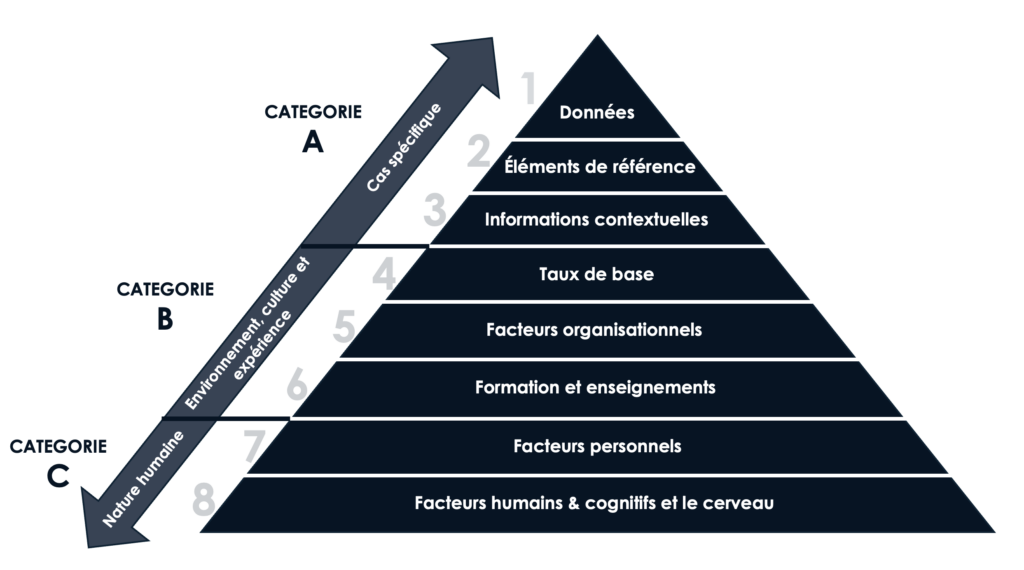
Fig. 2. Sources de biais cognitifs pouvant survenir lors de l’échantillonnage, des observations, des stratégies d’analyse, des tests et/ou des conclusions, et qui affectent même les experts. Ces sources de biais sont organisées selon une taxonomie en trois catégories : les sources propres au cas (Catégorie A), les sources propres à l’individu (Catégorie B), et les sources liées à la nature humaine (Catégorie C).
Limites de la méthode LSU
Par nature, la méthode LSU est limitée aux décisions comparatives, dans lesquelles des éléments provenant de la scène de crime (comme des traces papillaires ou des écrits manuscrits) sont comparés à un élément de référence ou à un suspect. Cette approche a d’abord été développée pour réduire les biais spécifiquement dans l’interprétation forensique de l’ADN (dévoilement séquentiel [3]). Dror et al. [4] ont ensuite élargi cette méthode à d’autres domaines forensiques comparatifs (empreintes digitales, armes à feu, écriture manuscrite, etc.) et ont proposé une approche équilibrée permettant la révision des jugements initiaux, mais dans des limites bien définies.
La méthode LSU présente donc deux limites principales : premièrement, elle ne s’applique qu’à un ensemble restreint de décisions comparatives (telles que la comparaison de profils ADN ou d’empreintes digitales). Deuxièmement, sa fonction se limite à la réduction des biais, sans agir sur la variabilité aléatoire (le « bruit ») ni améliorer plus globalement la qualité des décisions.
Dans cet article, nous introduisons une version étendue : le dévoilement linéaire et séquentiel — version étendue (LSU-E). Le LSU-E constitue une approche applicable à toutes les décisions forensiques, et non plus seulement aux décisions comparatives. De plus, le LSU-E va au-delà de la simple réduction des biais : il permet également de diminuer le bruit et d’améliorer la qualité des décisions de manière générale, en optimisant cognitivement la séquence d’accès à l’information, de façon à maximiser son utilité et, ce faisant, à produire des décisions plus fiables et de meilleure qualité.
Dévoilement linéaire et séquentiel – version étendue (LSU-E)
Au-delà du domaine forensique comparatif
La méthode LSU, dans sa forme actuelle, n’est applicable qu’aux domaines forensiques reposant sur la comparaison d’éléments de preuve avec des éléments de référence spécifiques (par exemple, le profil ADN ou les empreintes digitales d’un suspect — voir Niveau 2 dans la Fig. 2). Comme indiqué précédemment, le problème réside dans le fait que ces éléments de référence peuvent influencer la perception et l’interprétation des traces, au point que l’analyse d’un même élément de preuve peut varier selon la présence et la nature de l’élément de référence — et la méthode LSU vise précisément à réduire ce biais en imposant un raisonnement linéaire plutôt que circulaire.
Il risque de formuler des hypothèses et attentes a priori, ce qui peut orienter de manière biaisée sa perception, son interprétation de la scène et, en conséquence, les traces qu’il choisira ou non de collecter.
Cependant, de nombreux jugements forensiques ne reposent pas sur la comparaison entre deux stimuli. Par exemple, la criminalistique numérique, la pathologie médico-légale et l’investigation de la scène de crime nécessitent des prises de décision qui ne s’appuient pas sur la confrontation d’une trace à un suspect identifié. Même si ces domaines ne mettent pas en jeu une « cible » ou un stimulus de comparaison, ils sont néanmoins exposés à des informations contextuelles biaisantes susceptibles d’induire des attentes problématiques et des processus cognitifs descendants — et la version étendue LSU-E offre un moyen de minimiser ces effets.
Prenons, par exemple, le cas de la police scientifique. Les techniciens de scène de crime reçoivent souvent des informations sur la scène avant même d’y accéder physiquement, telles que la cause présumée du décès (homicide, suicide, accident) ou des hypothèses d’enquête (par exemple, le témoignage d’un témoin affirmant que le cambrioleur est entré par la fenêtre arrière, etc.). Lorsqu’un enquêteur reçoit ces éléments en amont de son observation directe de la scène, il risque de formuler des hypothèses et attentes a priori, ce qui peut orienter de manière biaisée sa perception, son interprétation de la scène et, en conséquence, les traces qu’il choisira ou non de collecter.
La même problématique s’applique à d’autres domaines non comparatifs comme la pathologie médico-légale, l’investigation d’incendies ou la criminalistique numérique. Par exemple, informer un expert en incendies avant même qu’il n’examine la scène qu’un bien immobilier était sur le marché depuis deux ans sans trouver d’acquéreur, ou que le propriétaire l’avait récemment assuré, peut orienter ses analyses et ses conclusions.
La lutte contre les biais dans ces domaines est d’autant plus complexe que les experts ont besoin d’un certain niveau d’information contextuelle pour exercer leur travail (contrairement, par exemple, aux experts en empreintes digitales, en balistique ou en ADN, qui peuvent effectuer leurs comparaisons avec un minimum de contexte).
L’objectif du LSU-E n’est pas de priver les experts des informations nécessaires, mais de réduire les biais en fournissant ces informations dans un ordre optimal. Le principe est simple : commencer toujours par les données ou éléments de preuve eux-mêmes — et uniquement ceux-ci — avant de prendre en compte tout autre élément contextuel, qu’il s’agisse d’informations explicites ou implicites, d’éléments de référence ou de toute autre donnée contextuelle ou méta-information.
Dans le cadre d’une investigation sur une scène de crime, par exemple, aucune information contextuelle ne devrait être communiquée à l’enquêteur ou au policier scientifique avant qu’il n’ait observé la scène de crime par lui-même et consigné ses premières impressions, fondées exclusivement sur ce qu’il voit sur les lieux. Ce n’est qu’ensuite qu’il pourra recevoir des informations contextuelles pertinentes avant de commencer la collecte d’indices. L’objectif est clair : dans la mesure du possible, les experts doivent, au moins dans un premier temps, se forger une opinion à partir des données brutes, avant d’être exposés à toute information susceptible d’influencer leur jugement.
Naturellement, le LSU-E ne se limite pas aux sciences forensiques et peut s’appliquer à de nombreux domaines d’expertise. Par exemple, en médecine, un médecin devrait examiner un patient avant d’établir un diagnostic (ou même de formuler une hypothèse) à partir d’informations contextuelles. Le protocole SBAR (Situation, Background, Assessment and Recommendation [49,50]) ne devrait être communiqué qu’après l’observation du patient. De même, un inspecteur de sécurité au travail ne devrait pas être informé des antécédents de non-conformité d’une entreprise avant d’avoir évalué le site de manière indépendante [32].
Au-delà de la réduction des biais
Au-delà de la question des biais, les décisions des experts gagnent en robustesse lorsqu’elles sont moins sujettes au bruit (variabilité aléatoire) et fondées sur les « bonnes » informations — c’est-à-dire les données les plus appropriées, fiables, pertinentes et diagnostiques. Le LSU-E propose des critères (décrits plus bas) permettant d’identifier et de hiérarchiser ces informations.
Plutôt que d’exposer les experts à l’information de manière aléatoire ou accidentelle, le LSU-E vise à optimiser la séquence d’accès à l’information, afin de neutraliser les effets cognitifs et psychologiques connus — tels que l’effet de primauté, l’attention sélective ou encore le biais de confirmation — et ainsi permettre aux experts de formuler de meilleures décisions.
Il est également essentiel que, au fur et à mesure de leur progression dans la séquence informationnelle, les experts documentent les informations auxquelles ils accèdent ainsi que toute évolution dans leur opinion. Cette exigence vise à garantir la transparence du processus décisionnel : elle permet de retracer précisément quelles informations ont été utilisées et comment elles ont influencé le jugement [51,52].
Critères de hiérarchisation de l’information dans le LSU-E
L’optimisation de l’ordre d’accès à l’information permet non seulement de réduire les biais, mais aussi de limiter le bruit et d’améliorer, de manière plus générale, la qualité des décisions. La question est alors la suivante : comment déterminer quelles informations doivent être fournies à l’expert, et dans quel ordre ? Le LSU-E propose trois critères pour établir une séquence optimale d’exposition à l’information pertinente : le pouvoir de biais, l’objectivité, et la pertinence — détaillés ci-dessous.
1. Pouvoir de biais.
Le pouvoir de biais d’une information pertinente peut varier considérablement. Certaines données peuvent avoir un fort potentiel de biais, tandis que d’autres n’en présentent pratiquement aucun. Par exemple, la technique utilisée pour relever et révéler une trace digitale présente un risque de biais minime (voire nul), alors que la présence d’un médicament à proximité d’un corps peut influencer l’interprétation quant à la cause du décès. Il est donc recommandé de présenter en premier les informations pertinentes les moins biaisantes, puis, dans un second temps, celles qui présentent un pouvoir de biais plus important.
2. Objectivité.
Les informations pertinentes diffèrent également quant à leur degré d’objectivité. Par exemple, le témoignage d’un témoin oculaire est généralement moins objectif qu’un enregistrement vidéo du même événement — mais même une vidéo peut varier en objectivité selon sa qualité, son angle, sa complétude, etc. Il est donc recommandé de faire précéder les informations plus objectives des informations moins objectives dans la séquence d’exposition.
3. Pertinence.
Certaines informations pertinentes sont centrales pour l’analyse et sous-tendent directement la décision à prendre, alors que d’autres sont plus périphériques ou accessoires. Par exemple, pour déterminer la cause du décès, la présence d’un médicament à côté du corps sera généralement plus pertinente (par exemple pour orienter les analyses toxicologiques) que des antécédents de dépression. Il est donc recommandé de présenter d’abord les informations les plus pertinentes, avant les informations secondaires. Bien entendu, toute information non pertinente à la décision (comme les antécédents judiciaires d’un suspect, si non directement liés) devrait être exclue de la séquence.
Ces critères doivent être considérés comme des principes directeurs, pour plusieurs raisons :
A. Les critères proposés s’inscrivent en réalité sur un continuum, et non dans des catégories binaires simples [45,48,53]. On peut même observer des variations au sein d’une même catégorie d’information : par exemple, une vidéo de meilleure qualité pourra être considérée avant une vidéo de qualité inférieure, ou la déclaration d’un témoin sobre pourra être considérée avant celle d’un témoin en état d’ébriété.
B. Ces trois critères ne sont pas indépendants ; ils interagissent entre eux. Par exemple, l’objectivité et la pertinence peuvent se combiner pour déterminer le poids d’une information : une donnée très objective aura un impact limité si sa pertinence est faible, et inversement, une information hautement pertinente perdra en valeur si son objectivité est faible. Ainsi, il ne faut pas évaluer ces critères isolément, mais en interaction.
C. L’ordre de présentation des informations doit être mis en balance avec les bénéfices potentiels qu’elles peuvent apporter [52]. Par exemple, lors du procès de l’agent de police Derek Chauvin pour la mort de George Floyd, le médecin légiste Andrew Baker a témoigné avoir délibérément choisi de ne pas visionner la vidéo de la mort de Floyd avant de pratiquer l’autopsie, afin d’éviter de biaiser son examen par des idées préconçues susceptibles de l’orienter dans une direction ou une autre [54]. Il a ainsi préféré d’abord examiner les données brutes (l’autopsie du corps), avant toute exposition à d’autres sources d’information (la vidéo). Une telle décision doit aussi considérer les bénéfices éventuels qu’aurait pu apporter le visionnage de la vidéo en amont de l’autopsie — par exemple si celle-ci pouvait orienter utilement l’examen plutôt que le biaiser. En d’autres termes, le LSU-E exige de pondérer les bénéfices potentiels par rapport au risque de biais que peut entraîner une information [52].
Par cette approche, nous encourageons les experts à examiner attentivement comment chaque élément d’information répond à chacun des trois critères, et à déterminer s’il doit être inclus ou non dans la séquence, et à quel moment. Dans la mesure du possible, ils devraient également documenter leur justification quant à l’inclusion ou l’exclusion de chaque information donnée. Bien entendu, cela soulève des questions pratiques quant à la mise en œuvre du LSU-E — comme le recours à des gestionnaires de cas (case managers). Les stratégies d’implémentation efficaces peuvent varier selon les disciplines ou les laboratoires, mais il est essentiel, dans un premier temps, de reconnaître ces enjeux et la nécessité de développer des approches pour y répondre.
Conclusion
Dans cet article, nous nous sommes appuyés sur les travaux classiques en psychologie cognitive portant sur les facteurs qui influencent et structurent la prise de décision experte, afin de proposer une approche large et polyvalente visant à renforcer la qualité des décisions des experts. Les spécialistes, quel que soit leur domaine, devraient commencer par se forger une première impression fondée exclusivement sur les données brutes ou les éléments de preuve, sans accès à un quelconque matériel de référence ni à un contexte — même si ces derniers sont pertinents. Ce n’est qu’ensuite qu’ils pourront envisager quelles autres informations doivent leur être communiquées, et dans quel ordre, en se basant sur leur objectivité, leur pertinence, et leur pouvoir de biais.
Il est par ailleurs essentiel de documenter de manière transparente l’impact et le rôle de chaque information dans le processus décisionnel. Grâce à l’utilisation du LSU-E, les décisions seront non seulement plus transparentes et moins sujettes au bruit, mais elles permettront également de s’assurer que la contribution de chaque élément d’information soit justifiée et proportionnelle à sa valeur probante.
Références
[1] S.E. Asche, Forming impressions of personality, J. Abnorm. Soc. Psychol., 41 (1964), pp. 258-290
[2] C.I. Hovland (Ed.), The Order of Presentation in Persuasion, Yale University Press (1957)
[3] D. Krane, S. Ford, J. Gilder, K. Inman, A. Jamieson, R. Koppl, et al. Sequential unmasking: a means of minimizing observer effects in forensic DNA interpretation, J. Forensic Sci., 53 (2008), pp. 1006-1107
[4] I.E. Dror, W.C. Thompson, C.A. Meissner, I. Kornfield, D. Krane, M. Saks, et al. Context management toolbox: a Linear Sequential Unmasking (LSU) approach for minimizing cognitive bias in forensic decision making, J. Forensic Sci., 60 (4) (2015), pp. 1111-1112
[5] F.H. Lund. The psychology of belief: IV. The law of primacy in persuasion, J. Abnorm. Soc. Psychol., 20 (1925), pp. 183-191
[6] B.B. Murdock Jr. The serial position effect of free recall, J. Exp. Psychol., 64 (5) (1962), p. 482
[7] J. Deese, R.A. Kaufman. Serial effects in recall of unorganized and sequentially organized verbal material, J. Exp. Psychol., 54 (3) (1957), p. 180
[8] J.M. Darley, P.H. Gross. A hypothesis-confirming bias in labeling effects,J. Pers. Soc. Psychol., 44 (1) (1983), pp. 20-33
[9] A. Treisman. Contextual cues in selective listening, Q. J. Exp. Psychol., 12 (1960), pp. 242-248
[10] J. Bargh, E. Morsella. The unconscious mind, Perspect. Psychol. Sci., 3 (1) (2008), pp. 73-79
[11] D.A. Broadbent. Perception and Communication, Pergamon Press, London, England (1958)
[12] J.A. Deutsch, D. Deutsch. Attention: some theoretical considerations, Psychol. Rev., 70 (1963), pp. 80-90
[13] A. Tversky, D. Kahneman. Judgment under uncertainty: heuristics and biases, Science, 185 (4157) (1974), pp. 1124-1131
[14] R.S. Nickerson. Confirmation bias: a ubiquitous phenomenon in many guises, Rev. Gen. Psychol., 2 (1998), pp. 175-220
[15] C. Barry, K. Halfmann. The effect of mindset on decision-making, J. Integrated Soc. Sci., 6 (2016), pp. 49-74
[16] P.C. Wason. On the failure to eliminate hypotheses in a conceptual task, Q. J. Exp. Psychol., 12 (3) (1960), pp. 129-140
[17] B.M. Staw. The escalation of commitment: an update and appraisal, Z. Shapira (Ed.), Organizational Decision Making, Cambridge University Press (1997), pp. 191-215
[18] M. Sherif, D. Taub, C.I. Hovland. Assimilation and contrast effects of anchoring stimuli on judgments, J. Exp. Psychol., 55 (2) (1958), pp. 150-155
[19] C.A. Anderson, M.R. Lepper, L. Ross. Perseverance of social theories: the role of explanation in the persistence of discredited information, J. Pers. Soc. Psychol., 39 (6) (1980), pp. 1037-1049
[20] M.L. Dean. Presentation order effects in product taste tests, J. Psychol., 105 (1) (1980), pp. 107-110
[21] K.A. Carlson, J.E. Russo. Biased interpretation of evidence by mock jurors, J. Exp. Psychol. Appl., 7 (2) (2001), p. 91
[22] R.G. Lawson. Order of presentation as a factor in jury persuasion. Ky, LJ, 56 (1967), p. 523
[23] D. Jolley, K.M. Douglas. Prevention is better than cure: addressing anti-vaccine conspiracy theories, J. Appl. Soc. Psychol., 47 (2017), pp. 459-469
[24] A.R. Klales, K.M. Lesciotto. The “science of science”: examining bias in forensic anthropology, Proceedings of the 68th Annual Scientific Meeting of the American Academy of Forensic Sciences (2016)
[25] M. Davidson, C. Rando, S. Nakhaeizadeh. Cognitive bias and the order of examination on skeletal remains, Proceedings of the 71st Annual Meeting of the American Academy of Forensic Sciences (2019)
[26] D. Kahneman, O. Sibony, C. Sunstein. Noise: A Flaw in Human Judgment, William Collins (2021)
[27] I.E. Dror. Cognitive and human factors in expert decision making: six fallacies and the eight sources of bias, Anal. Chem., 92 (12) (2020), pp. 7998-8004
[28] J. Kukucka, S.M. Kassin, P.A. Zapf, I.E. Dror. Cognitive bias and blindness: a global survey of forensic science examiners, Journal of Applied Research in Memory and Cognition, 6 (2017), pp. 452-459
[29] I.E. Dror. The paradox of human expertise: why experts get it wrong, N. Kapur (Ed.), The Paradoxical Brain, Cambridge University Press, Cambridge, UK (2011), pp. 177-188
[30] C. Eeden, C. De Poot, P. Koppen. The forensic confirmation bias: a comparison between experts and novices, J. Forensic Sci., 64 (1) (2019), pp. 120-126
[31] C. Huang, R. Bull. Applying Hierarchy of Expert Performance (HEP) to investigative interview evaluation: strengths, challenges and future directions, Psychiatr. Psychol. Law, 28 (2021)
[32] C. MacLean, I.E. Dror. The effect of contextual information on professional judgment: reliability and biasability of expert workplace safety inspectors,J. Saf. Res., 77 (2021), pp. 13-22
[33] E. Rassin. Anyone who commits such a cruel crime, must be criminally irresponsible’: context effects in forensic psychological assessment, Psychiatr. Psychol. Law (2021)
[34] V. Meterko, G. Cooper. Cognitive biases in criminal case evaluation: a review of the research, J. Police Crim. Psychol. (2021)
[35] C. FitzGerald, S. Hurst. Implicit bias in healthcare professionals: a systematic review, BMC Med. Ethics, 18 (2017), pp. 1-18
[36] M.K. Goyal, N. Kuppermann, S.D. Cleary, S.J. Teach, J.M. Chamberlain. Racial disparities in pain management of children with appendicitis in emergency departments, JAMA Pediatr, 169 (11) (2015), pp. 996-1002
[37] I.E. Dror. Biases in forensic experts, Science, 360 (6386) (2018), p. 243
[38] S.M. Kassin, I.E. Dror, J. Kukucka. The forensic confirmation bias: problems, perspectives, and proposed solutions, Journal of Applied Research in Memory and Cognition, 2 (1) (2013), pp. 42-52
[39] NAS. National Research Council, Strengthening Forensic Science in the United States: a Path Forward, National Academy of Sciences (2009)
[40] PCAST, President’s Council of Advisors on science and Technology (PCAST), Report to the President – Forensic Science in Criminal Courts: Ensuring Validity of Feature-Comparison Methods, Office of Science and Technology, Washington, DC (2016)
[41] NCFS, National Commission on Forensic Science. Ensuring that Forensic Analysis Is Based upon Task-Relevant Information, National Commission on Forensic Science, Washington, DC (2016)
[42] Forensic Science Regulator. Cognitive bias effects relevant to forensic science examinations, disponible sur https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/914259/217_FSR-G-217_Cognitive_bias_appendix_Issue_2.pdf
[43] ANZPAA, A Review of Contextual Bias in Forensic Science and its Potential Legal Implication, Australia New Zealand Policing Advisory Agency (2010)
[44] J. Kukucka, I.E. Dror. Human factors in forensic science: psychological causes of bias and error, D. DeMatteo, K.C. Scherr (Eds.), The Oxford Handbook of Psychology and Law, Oxford University Press, New York (2021)
[45] I.E. Dror, J. Melinek, J.L. Arden, J. Kukucka, S. Hawkins, J. Carter, D.S. Atherton. Cognitive bias in forensic pathology decisions, J. Forensic Sci., 66 (4) (2021)
[46] N. Sunde, I.E. Dror. A hierarchy of expert performance (HEP) applied to digital forensics: reliability and biasability in digital forensics decision making, Forensic Sci. Int.: Digit. Invest., 37 (2021)
[47] D.C. Murrie, M.T. Boccaccini, L.A. Guarnera, K.A. Rufino. Are forensic experts biased by the side that retained them? Psychol. Sci., 24 (10) (2013), pp. 1889-1897
[48] G. Langenburg. Addressing potential observer effects in forensic science: a perspective from a forensic scientist who uses linear sequential unmasking techniques, Aust. J. Forensic Sci., 49 (2017), pp. 548-563
[49] C.M. Thomas, E. Bertram, D. Johnson. The SBAR communication technique, Nurse Educat., 34 (4) (2009), pp. 176-180
[50] I. Wacogne, V. Diwakar. Handover and note-keeping: the SBAR approach, Clin. Risk, 16 (5) (2010), pp. 173-175
[51] M.A. Almazrouei, I.E. Dror, R. Morgan. The forensic disclosure model: what should be disclosed to, and by, forensic experts?, International Journal of Law, Crime and Justice, 59 (2019)
[52] I.E. Dror. Combating bias: the next step in fighting cognitive and psychological contamination, J. Forensic Sci., 57 (1) (2012), pp. 276-277
[53] D. Simon, Minimizing Error and Bias in Death Investigations, vol. 49, Seton Hall Law Rev. (2018), pp. 255-305
[54] CNN. Medical examiner: I « intentionally chose not » to view videos of Floyd’s death before conducting autopsy, April 9, 2021, disponible sur https://edition.cnn.com/us/live-news/derek-chauvin-trial-04-09-21/h_03cda59afac6532a0fb8ed48244e44a0 (2011)